Contents
背景
对于一些重要应用,我们希望实现高可用(High-Availability). 在 RHEL7 中,可以使用 Pacemaker 达到这样的效果。
Pacemaker 是一个集群资源管理器,它负责管理集群环境中资源(服务)的整个生命周期。除了传统意义上的 Active/Passive 高可用,Pacemaker 可以灵活管理各节点上的不同资源,实现如 Active/Active,或者多活多备等架构。
下图是一个经典的 Active/Passive 高可用例子, Host1/Host2 只有一台服务器在提供服务,另一台服务器作为备机时刻准备着接管服务。
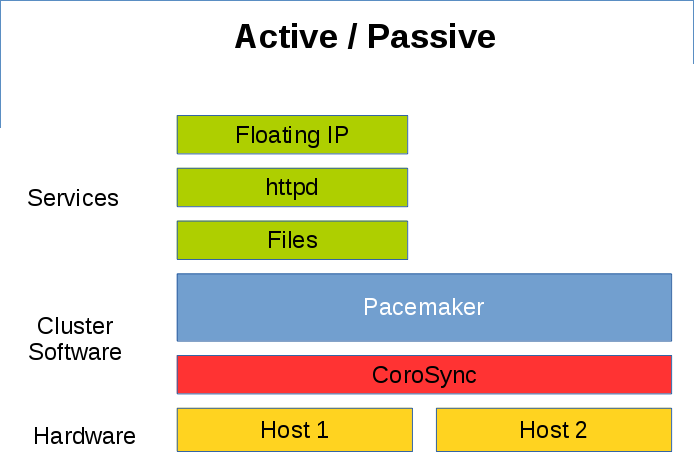
为了节省服务器资源,有时候可以采取 Shared Failover 的策略,两台服务器同时提供不同的服务,留有一台备用服务器接管失效的服务。
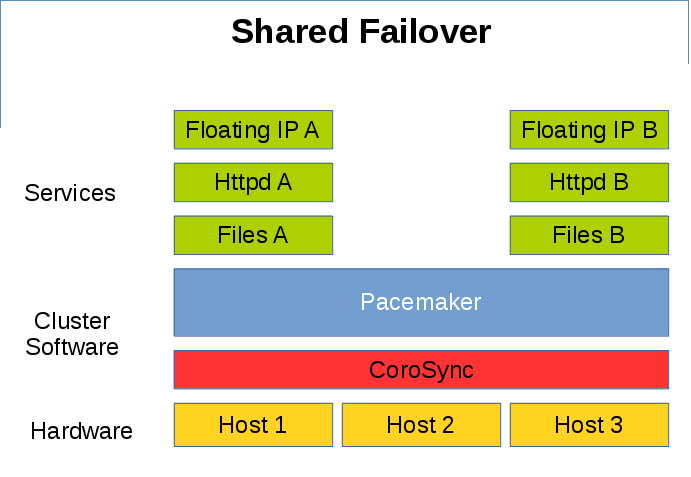
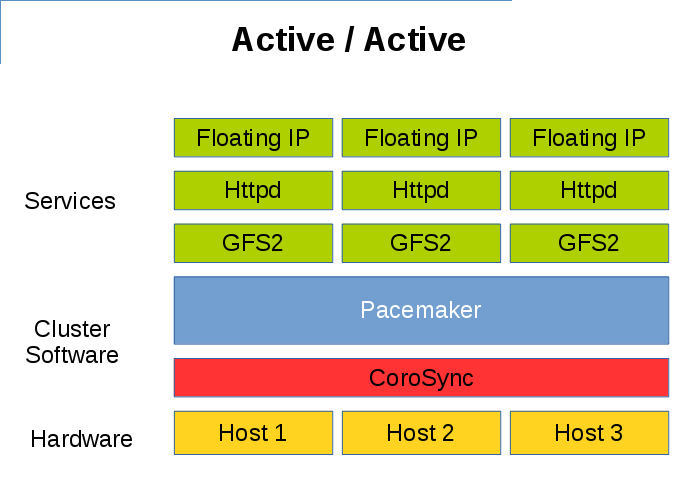
通过共享文件系统如 GFS2,也可以实现 Active/Active 的多活形式。
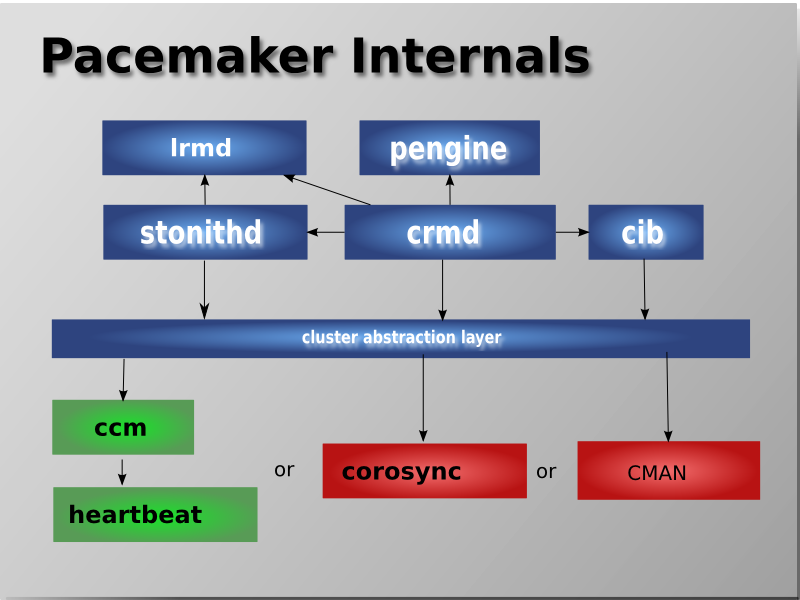
Pacemaker 内部构成
Pacemaker 主要由以下部件组成:
CIB - Cluster Information Base
CRMd - Cluster Resource Management daemon
LRMd - Local Resource Management daemon
PEngine - Policy Engine
STONITHd - Fencing daemon
消息传递层 (Messaging and Infrastructure Layer)
这是最基础的一层,集群需要依靠这一层来正常工作。这一层主要的工作是向外发出“我还活着”的信息,以及其他交换信息。RHEL7 HA-Addon 使用的是 Corosync 项目。
资源管理层 (Resource Allocation Layer)
上面一层是资源管理层,这一层是 Pacemaker 的核心,也是结构相对复杂的一层。它由以下组件构成:
Cluster Resource Manager (CRM)
在这一层中,每个动作都需要 CRM 来进行沟通协调。在每个节点上,CRM 都会维护一个 CIB 来记录状态信息。
Cluster Information Base (CIB)
CIB 是一个 in-memory XML, 它记录着整个集群的配置和当前状态。每个节点上都有一个 CIB, DC 节点上的 CIB 是 Master CIB, 它会自动同步所有变更到其他节点上。
Designated Coordinator (DC)
每个节点上都运行着 CRM,其中一个节点的 CRM 会被选举为 DC。 DC 是集群中唯一可以决定集群层面可以做什么变化的 CRM,比如说 fencing 或者移动一个资源。
每当集群中的成员出现变化时,会自动重新选举 DC。
Policy Engine (PE)
在 DC 需要对事件进行应对时(比如集群状态出现变化), PE 会根据配置和当前的状态,计算出集群应有的下一个状态,以及行动计划 (transition graph),DC 会根据行动计划执行相应的动作。
Local Resource Manager (LRM)
LRM 是本地资源管理器,它会根据 CRM 的指令,调用本地的 Resource Agents,实现对资源的启动/停止/监控动作,它还会将这些动作的结果反馈给本地的 CRM.
Shoot The Other Node In The Head (Stonith)
工作流 - 这些组件是怎样协同工作的?
- 在集群启动时,首先会建立起 Corosync 的通信,使节点能互相“看见对方”。
- 每一个节点上都会启动一个 crmd 后台进程,它们会自动选举其中一个节点上的 crmd 作为 DC. DC 上的 CIB 是 Master CIB, 它的变更会自动同步到其他节点上。
- 很多动作,比如增加/移除资源,增加/移除资源约束,都会引起集群层面的变化。比如,我们要添加一个虚拟IP资源。我们可以在任一节点上,通过管理工具添加一个虚拟IP资源,它会告知 DC,DC 会修改相应的 CIB 并同步到所以节点中。
- 基于变化了的 CIB, PE 会计算当前配置和状态对应的下一个应有的状态,同时 PE 会计算出实现这个状态的行动计划,告知 DC.
- DC 得到行动计划后,会想相应节点的 CRM 发送指令,相应节点的 CRM 接收到指令后会调用它本地的 LRM 对资源进行操作。
- 每个节点的 LRM 进行完操作后,会将结果报告本地的 CRM,随后每个节点的 CRM 会将结果汇报给 DC, DC 再进行后续决定。
- 在某些情况下,需要 fence 某个节点(比如丢心跳的时候),这时候会调用 stonith 来进行操作。
成员管理 - Corosync 2.x 特性
要使集群工作,存活的节点数量必须要满足 quorum = expected vote / 2 + 1, 即需要集群中大于半数的节点才能正常提供服务。
在 RHEL7 中, Corosync 使用 UDPU 作为默认的通信协议。(RHEL6 的 cman + rgmanager 架构中,默认使用 multicast). 如果需要改为 Multicast, 可以在 /etc/corosync/corosync.conf 中进行修改。
RHEL7 中使用的是 Corosync 2. 相对与 Corosync/cman, 它提供了以下的新选项。
two_node
two_node 是从 cman 时代就开始存在的选项。它是为“两节点集群”而设计的。按照正常计算,两节点集群需要获得2票(两个节点都存活)才能工作, quorum = 2 / 2 + 1 = 2. 而这就无法达到高可用的效果。
设置 two_node 模式后,集群只需要1票即可工作。为了避免 split-brain 的问题,两个节点的 fence 和心跳需要使用同一个网络。(如果某个节点断网了,它就不能去 fence 另一节点,而另一个未断网的节点则可以 fence 该节点)。
设置了 two_node 之后, wait_for_all 选项也会默认开启,以避免 fence_loop.
wait_for_all
如果全新启动一个集群(全新启动:集群启动前所有节点都没有加入这个集群),wait_for_all 会对比已加入节点的数量是否与 expected vote 相等,在所有节点都顺利加入集群后,才会变成 quorate 状态。
如果不设置 wait_for_all, 只要节点数到达 expect_vote/2 + 1 这部分节点就会开始提供服务。对于两节点的集群,wait_for_all 非常重要,如果不设置 wait_for_all,会导致 fence loop.
auto_tie_breaker
在遇到 50/50 的脑裂情况的时候,比如4节点集群出现 2 个节点 + 2 个节点 的分裂情况,按照 quorum = expected vote / 2 + 1, 两边都不能达到 quorate 的状态。 默认配置下, auto_tie_breaker 可以使拥有“最小节点序号”的一边达到 quorate 状态,使之能继续提供服务。
Auto_tie_breaker 只应该用于偶数节点数的集群,但不能用于 2 节点集群。(2 节点集群应使用 two_node 选项)
last_man_standing & last_man_standing_window
假设有个8节点集群,在默认情况下,它需要 8/2+1=5 个节点在集群中才能提供服务。也就是说,好不容易买了8台服务器,而只能容忍3台挂掉。在某些情况下,我们希望这个8节点集群能在只剩2个节点的时候还能提供服务,这时候 last_man_standing 就能派上用场了。
设置了 last_man_standing 之后,如果集群中有节点被 fence,剩余节点中的 expected votes 会在 last_man_standing_window (默认10秒)后,自动减少至当前节点数量。要留意的是,剩余节点的数量首先需要达到 quorate 才能进行这样的减少 expected_votes 的动作。通过这样的操作,能允许 quorate 一边的节点数量逐渐减少至 2 还能提供服务。
corosync_votequorum 的 man 手册里有这么个例子:
provider: corosync_votequorum
expected_votes: 8
wait_for_all: 1
last_man_standing: 1
last_man_standing_window: 10000
}
Example chain of events:
a. The cluster is fully operational with 8 nodes. (expected_votes: 8 quorum: 5)
b. 3 nodes die, cluster is quorate with 5 nodes.
c. After last_man_standing_window timer expires, expected_votes and quorum are recalculated. (expected_votes: 5 quorum: 3)
d. At this point, 2 more nodes can die and cluster will still be quorate with 3.
e. Once again, after last_man_standing_window timer expires expected_votes and quorum are recalculated. (expected_votes: 3 quorum: 2)
f. At this point, 1 more node can die and cluster will still be quorate with 2.
g. After one more last_man_standing_window timer (expected_votes: 2 quorum: 2)
在正常情况下, last_man_standing 只能允许节点数量减少至 2。如果需要省下 1 个节点也能提供服务,则需要同时设置 auto_tie_breaker.
资源约束 - Constrains
相比于 rgmanager 通过将资源组合成服务的管理方式, pacemaker 可以直接对资源设置各类约束,使资源管理更加灵活。
Pacemaker 可以对资源设置以下约束(Constrains):
order
order 主要定义资源的启动/停止顺序。
在 pcs 中,定义 order 约束的命令是:
比如, 设置 start
location
location 主要定义资源应该在哪个节点上启动。
在 pcs 中,定义 location 约束的命令是:
<resource id> prefers <node[=score]>
<resource id> avoids <node[=score]>
在 pacemaker 中,每个 <资源,节点> 的组合都会有一个对应的分数(score), pacemaker 会把资源启动在分数最高的可用节点上。在命令中,如果不指定分数, prefers 默认会将分数设置为 INFINITY, avoids 则会将分数设置为 -INFINITY.
比如,设置
那么,在 pcmk-node1 可用的情况下, vip-1 将会在 pcmk1-node1 上启动。
colocation
colocation 主要定义资源与资源间的位置关系。
在 pcs 中,可以通过以下命令设置 colocation 约束:
Pacemaker 首先会决定在哪个节点上启动
rules
通常用不上,如有需要请参考官方文档: https://clusterlabs.org/doc/en-US/Pacemaker/1.1/html/Pacemaker_Explained/ch08.html
特殊资源 - resource group
Resource group 是一种特殊的资源。它默认包含了 order + colocation. 比如,一个 resource group 包含以下 resources:
- httpd
- vip
这意味着,启动顺序是 filesystem -> httpd -> vip,停止顺序是 vip -> httpd -> filesystem. 而且这3个资源会在同一个节点上运行。
设置资源组之后,无须再对组内资源配置约束条件。
支持范围与限制
搭建一个集群,首先要符合国家相关法律法规,然后需要满足以下基本条件:
- 在 RHEL7 的支持策略中,节点数量不能超过 16 个;
- // TODO 节点通信延时?
- 节点间不能通过网线直连,必须经过交换机;
- 必须要有 Power fence 的设备,比如 iLo 控制卡,VMware soap 等;
更详细的支持策略,可参考:
https://access.redhat.com/articles/2912891
Demo: 搭建一个HA集群
准备工作
配置各节点的 hostname
在搭建集群之前,首先要给个节点分配一个静态IP,然后将各节点的 hostname 和 IP 信息写到 /etc/hosts 中。写到 /etc/hosts 中而不是使用 DNS 的原因,是 DNS 可能会有很长延迟,或者 DNS 可能会因为各种原因不返回,这将可能导致心跳丢失,pacemaker 服务不可用等问题。
192.168.122.12 node2 node2.example.com
配置 NTP 保证各节点时间准确
每个节点的时间需要同步,否则出现问题的时候将难以从日志中对比线索。
安装所需软件包
在 RHEL7 中,可以通过以下命令安装 pacemaker 所需的软件包:
另外,集群中各节点的软件版本,比如 kernel, corosync, pacemaker 应该保持一致。
启动 pcsd 服务
[root@node1 ~]# systemctl start pcsd
[root@node2 ~]# systemctl enable pcsd
[root@node2 ~]# systemctl start pcsd
防火墙
在每个节点上执行以下命令,允许心跳以及pcs管理工具的通信。
[root@node2 ~]# firewall-cmd --add-service=high-availability
[root@node1 ~]# firewall-cmd --permanent --add-service=high-availability
[root@node2 ~]# firewall-cmd --permanent --add-service=high-availability
认证各节点的 pcs
认证各个节点的 pcs, 使得 pcs 这个管理工具能访问各节点。(需要在所有节点上给 hacluster 设置相同的密码)
[root@node2 ~]# echo redhat | passwd --stdin hacluster
在任一节点执行,建立起各个节点之间的认证关系。
Username: hacluster
Password:
node1: Authorized
node2: Authorized
建立集群
在任一节点执行:
这个命令会创建一个名为 mycluster 的集群,其中包含 node1 和 node2 两个节点。--start 表示在集群建立完成后自动启动该集群。
通过 pcs status 命令,可以验证该集群已经建立并正常通信。
Cluster name: mycluster <<---------
WARNING: no stonith devices and stonith-enabled is not false
Stack: corosync
Current DC: node2 (version 1.1.16-12.el7-94ff4df) - partition with quorum
Last updated: Fri Aug 18 13:10:49 2017
Last change: Fri Aug 18 13:10:42 2017 by hacluster via crmd on node2
2 nodes configured
0 resources configured
Online: [ node1 node2 ] <<---------
配置 Fence - Stonith
当节点出现故障时,Pacemaker 会进行资源切换,把运行在故障节点上的资源切换到正常运行的节点上,以保证服务的高可用。
如果节点没有响应,处于“大多数”(quorate)状态的节点会杀掉没有响应的节点,以:
1. 使集群成员状态明确(不希望有节点处于“生死未卜”状态);
2. 确保没有响应的节点不能够访问存储;
杀掉节点的行为我们可以成为 fence. Pacemaker 中, fence 由 Stonith 进行管理。
手动测试 fence agent
在 KVM 实验环境中,可以使用 fence_xvm 作为 fence agent.
1. 把 KVM Host 中预先生成的 /etc/cluster/fence_xvm.key 复制到 node1 和 node2 的 /etc/cluster/fence_xvm.key 中;
2. 在两个节点上放行 1229 端口:
[root@node2 ~]# firewall-cmd --permanent --add-port="1229/udp" --add-port="1229/tcp"
[root@node1 ~]# firewall-cmd --reload
[root@node2 ~]# firewall-cmd --reload
3. 测试能否通过 fence_xvm 获取虚拟机信息:
Status: ON
[root@node2 ~]# fence_xvm -H feichashao_RHEL74_node1 -o status
Status: ON
4. 尝试通过 fence agent 进行 fence. 可以观察到, node2 会被 fence. 同理,测试对 node1 的 fence.
配置 stonith
确认 fence agent 没有问题之后,可以使用 pcs 配置 stonith.
[root@node1 ~]# pcs stonith create fence_node2 fence_xvm port=feichashao_RHEL74_node2 pcmk_host_list=node2
测试能否通过 stonith 进行 fence.
Node: node2 fenced
拔网线测试
如果使用物理机,可以通过拔网线的方式来测试当心跳丢失后,节点能否被顺利 fence. 切勿使用如"ifdown"/"ip link down"的方式进行测试。
添加服务 - Resource
[root@node2 ~]# yum install -y httpd
[root@node1 ~]# pcs resource create httpd apache configfile="/etc/httpd/conf/httpd.conf" --group webservice
[root@node1 ~]# pcs resource create vip IPaddr2 ip=192.168.122.11 cidr_netmask=24 --group webservice
[root@node1 ~]# pcs resource
Resource Group: webservice
html-fs (ocf::heartbeat:Filesystem): Started node1
httpd (ocf::heartbeat:apache): Started node1
vip (ocf::heartbeat:IPaddr2): Started node1
测试验证
测试能否通过vip访问网页服务。
This is a HA web server.
测试 httpd 意外退出时能否重启
## /var/log/messages
Aug 19 19:41:34 node1 apache(httpd)[9201]: INFO: apache not running
Aug 19 19:41:34 node1 crmd[1671]: notice: State transition S_IDLE -> S_POLICY_ENGINE
Aug 19 19:41:34 node1 pengine[1670]: warning: Processing failed op monitor for httpd on node1: not running (7)
Aug 19 19:41:34 node1 pengine[1670]: notice: Recover httpd#011(Started node1)
Aug 19 19:41:34 node1 pengine[1670]: notice: Restart vip#011(Started node1)
Aug 19 19:41:34 node1 pengine[1670]: notice: Calculated transition 158, saving inputs in /var/lib/pacemaker/pengine/pe-input-57.bz2
Aug 19 19:41:34 node1 pengine[1670]: warning: Processing failed op monitor for httpd on node1: not running (7)
Aug 19 19:41:34 node1 pengine[1670]: notice: Recover httpd#011(Started node1)
Aug 19 19:41:34 node1 pengine[1670]: notice: Restart vip#011(Started node1)
Aug 19 19:41:34 node1 pengine[1670]: notice: Calculated transition 159, saving inputs in /var/lib/pacemaker/pengine/pe-input-58.bz2
Aug 19 19:41:34 node1 crmd[1671]: notice: Initiating stop operation vip_stop_0 locally on node1
Aug 19 19:41:34 node1 IPaddr2(vip)[9247]: INFO: IP status = ok, IP_CIP=
Aug 19 19:41:34 node1 crmd[1671]: notice: Result of stop operation for vip on node1: 0 (ok)
Aug 19 19:41:34 node1 crmd[1671]: notice: Initiating stop operation httpd_stop_0 locally on node1
Aug 19 19:41:34 node1 apache(httpd)[9302]: INFO: apache is not running.
Aug 19 19:41:34 node1 crmd[1671]: notice: Result of stop operation for httpd on node1: 0 (ok)
Aug 19 19:41:34 node1 crmd[1671]: notice: Initiating start operation httpd_start_0 locally on node1
Aug 19 19:41:34 node1 apache(httpd)[9349]: INFO: AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using node1.example.com. Set the 'ServerName' directive globally to suppress this message
Aug 19 19:41:34 node1 apache(httpd)[9349]: INFO: Successfully retrieved http header at http://localhost:80
Aug 19 19:41:34 node1 crmd[1671]: notice: Result of start operation for httpd on node1: 0 (ok)
Aug 19 19:41:34 node1 crmd[1671]: notice: Initiating monitor operation httpd_monitor_10000 locally on node1
Aug 19 19:41:34 node1 crmd[1671]: notice: Initiating start operation vip_start_0 locally on node1
Aug 19 19:41:34 node1 IPaddr2(vip)[9434]: INFO: Adding inet address 192.168.122.11/24 with broadcast address 192.168.122.255 to device ens3
Aug 19 19:41:34 node1 IPaddr2(vip)[9434]: INFO: Bringing device ens3 up
Aug 19 19:41:34 node1 apache(httpd)[9433]: INFO: Successfully retrieved http header at http://localhost:80
Aug 19 19:41:34 node1 IPaddr2(vip)[9434]: INFO: /usr/libexec/heartbeat/send_arp -i 200 -c 5 -p /var/run/resource-agents/send_arp-192.168.122.11 -I ens3 -m auto 192.168.122.11
Aug 19 19:41:38 node1 crmd[1671]: notice: Result of start operation for vip on node1: 0 (ok)
Aug 19 19:41:38 node1 crmd[1671]: notice: Initiating monitor operation vip_monitor_10000 locally on node1
Aug 19 19:41:38 node1 crmd[1671]: notice: Transition 159 (Complete=11, Pending=0, Fired=0, Skipped=0, Incomplete=0, Source=/var/lib/pacemaker/pengine/pe-input-58.bz2): Complete
Aug 19 19:41:38 node1 crmd[1671]: notice: State transition S_TRANSITION_ENGINE -> S_IDLE
Aug 19 19:41:44 node1 apache(httpd)[9652]: INFO: Successfully retrieved http header at http://localhost:80
[root@node1 ~]# curl 192.168.122.11
This is a HA web server.
在 KVM 中,对 node1 按下“暂停”键,模拟 node1 无响应的情况。
Aug 19 19:58:04 node2 corosync[1628]: [TOTEM ] A processor failed, forming new configuration.
Aug 19 19:58:05 node2 corosync[1628]: [TOTEM ] A new membership (192.168.122.230:36) was formed. Members left: 1
Aug 19 19:58:05 node2 corosync[1628]: [TOTEM ] Failed to receive the leave message. failed: 1
Aug 19 19:58:05 node2 corosync[1628]: [QUORUM] Members[1]: 2
Aug 19 19:58:05 node2 corosync[1628]: [MAIN ] Completed service synchronization, ready to provide service.
Aug 19 19:58:05 node2 stonith-ng[1637]: notice: Node node1 state is now lost
Aug 19 19:58:05 node2 pacemakerd[1635]: notice: Node node1 state is now lost
Aug 19 19:58:05 node2 cib[1636]: notice: Node node1 state is now lost
Aug 19 19:58:05 node2 cib[1636]: notice: Purged 1 peers with id=1 and/or uname=node1 from the membership cache
Aug 19 19:58:05 node2 attrd[1639]: notice: Node node1 state is now lost
Aug 19 19:58:05 node2 attrd[1639]: notice: Removing all node1 attributes for peer loss
Aug 19 19:58:05 node2 attrd[1639]: notice: Lost attribute writer node1
Aug 19 19:58:05 node2 attrd[1639]: notice: Purged 1 peers with id=1 and/or uname=node1 from the membership cache
Aug 19 19:58:05 node2 crmd[1641]: notice: Node node1 state is now lost
Aug 19 19:58:05 node2 crmd[1641]: warning: Our DC node (node1) left the cluster
Aug 19 19:58:05 node2 crmd[1641]: notice: State transition S_NOT_DC -> S_ELECTION
Aug 19 19:58:05 node2 stonith-ng[1637]: notice: Purged 1 peers with id=1 and/or uname=node1 from the membership cache
Aug 19 19:58:05 node2 crmd[1641]: notice: State transition S_ELECTION -> S_INTEGRATION
Aug 19 19:58:05 node2 crmd[1641]: warning: Input I_ELECTION_DC received in state S_INTEGRATION from do_election_check
Aug 19 19:58:07 node2 pengine[1640]: warning: Node node1 will be fenced because the node is no longer part of the cluster
Aug 19 19:58:07 node2 pengine[1640]: warning: Node node1 is unclean
Aug 19 19:58:07 node2 pengine[1640]: warning: Processing failed op monitor for httpd on node1: not running (7)
Aug 19 19:58:07 node2 pengine[1640]: warning: Action fence_node1_stop_0 on node1 is unrunnable (offline)
Aug 19 19:58:07 node2 pengine[1640]: warning: Action html-fs_stop_0 on node1 is unrunnable (offline)
Aug 19 19:58:07 node2 pengine[1640]: warning: Action httpd_stop_0 on node1 is unrunnable (offline)
Aug 19 19:58:07 node2 pengine[1640]: warning: Action vip_stop_0 on node1 is unrunnable (offline)
Aug 19 19:58:07 node2 pengine[1640]: warning: Scheduling Node node1 for STONITH
Aug 19 19:58:07 node2 pengine[1640]: notice: Move fence_node1#011(Started node1 -> node2)
Aug 19 19:58:07 node2 pengine[1640]: notice: Move html-fs#011(Started node1 -> node2)
Aug 19 19:58:07 node2 pengine[1640]: notice: Move httpd#011(Started node1 -> node2)
Aug 19 19:58:07 node2 pengine[1640]: notice: Move vip#011(Started node1 -> node2)
Aug 19 19:58:07 node2 pengine[1640]: warning: Calculated transition 0 (with warnings), saving inputs in /var/lib/pacemaker/pengine/pe-warn-0.bz2
Aug 19 19:58:07 node2 crmd[1641]: notice: Requesting fencing (reboot) of node node1
Aug 19 19:58:07 node2 crmd[1641]: notice: Initiating start operation fence_node1_start_0 locally on node2
常见错误排查
心跳丢失
心跳丢失主要的现象是节点被 fence,随之发生资源切换。
发生心跳丢失,首先需要排查网络情况,心跳丢失很有可能是由于网络错误或者拥塞导致的。另外需要排查系统负载,如果系统负载过高使得 corosync 没有被及时调度,那么 corosync 可能来不及发出心跳,导致被其他节点 fence.
接下来还可以排查节点的电源情况,以及是否发生过 kernel panic.
对于网络问题,可以在搭建集群的时候,通过配置网卡 bonding 或者 冗余心跳 (rrp)来预防。
fence 失败
fence 失败的主要现象是节点无法被 fence,导致其他节点无法启动资源。
可以查看 stonith 相关日志来排查原因。
Aug 21 14:39:53 node1 crmd[23707]: notice: Peer node2 was not terminated (reboot) by <anyone> for node1: No route to host (ref=4d6457ee-cef8-4a20-9891-3b7c0c1c56d7) by client stonith_admin.25479
资源切换/资源无法启动
当出现了资源 monitor 失败或者资源无法启动,可以检查 crmd/lrmd 相关的日志,查看失败原因。
Aug 19 19:58:10 node2 crmd[1641]: notice: node2-html-fs_start_0:67 [ mount: can't find UUID="df102cd7-adb0-4272-a079-8c194f74408e"\nocf-exit-reason:Couldn't mount filesystem -U df102cd7-adb0-4272-a079-8c194f74408e on /var/www/html\n ]
参考资料
[1] Pacemaker Explained (http://clusterlabs.org/doc/en-US/Pacemaker/1.1-pcs/pdf/Pacemaker_Explained/Pacemaker-1.1-Pacemaker_Explained-en-US.pdf)
[2] Clusters from Scratch (http://clusterlabs.org/doc/en-US/Pacemaker/1.1-pcs/pdf/Clusters_from_Scratch/Pacemaker-1.1-Clusters_from_Scratch-en-US.pdf)
[3] New quorum features in Corosync 2 (http://people.redhat.com/ccaulfie/docs/Votequorum_Intro.pdf)
[4] The OCF Resource Agent Developer's Guide (https://github.com/ClusterLabs/resource-agents/blob/master/doc/dev-guides/ra-dev-guide.txt)