之前做的笔记。
(更多…)
分类: Linux
Linux, RHEL, CentOS, etc.
-
crash 分析 vmcore 的常用命令
-
Elasticsearch 删除 RED state index
问题
Openshift v4 中的 logging 出现了某些问题,导致 Elasticsearch 处于 red state, 日志无法写入。
解决方法
1. 进入到 ES Pod 中,查看健康状态,发现是 red 的,有一些 unassigned shard.
[cc lang=”text”]
$ oc exec -it elasticsearch-cdm-xxxx-1-yyyy-zzzz -n openshift-logging bash
bash-4.2$ health
Tue Nov 10 06:19:00 UTC 2020
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
xxxxx 06:19:00 elasticsearch red 3 3 578 289 0 0 202 0 – 74.1%
[/cc]2. 查看有哪些 unassigned shards, 以及 unassigned 的原因。集群刚刚恢复的时候,shard 的状态会是 CLUSTER_RECOVERED,但不应该持续很久。这里的状态一直停留在 CLUSTER_RECOVERED,应该是什么地方出现了问题。
[cc lang=”text”]
bash-4.2$ $curl_get “$ES_BASE/_cat/shards?h=index,shard,prirep,state,unassigned.reason” | grep UNASSIGNED
.xxxxxxxxxx.2020.10.14 1 p UNASSIGNED CLUSTER_RECOVERED
.xxxxxxxxxx.2020.10.14 1 r UNASSIGNED CLUSTER_RECOVERED
.xxxxxxxxxx.2020.10.14 2 p UNASSIGNED CLUSTER_RECOVERED
[/cc]3. 查看 Unassigned 的原因。数据没了。
[cc lang=”text”]
bash-4.2$ $curl_get “$ES_BASE/_cluster/allocation/explain?pretty”
“can_allocate” : “no_valid_shard_copy”,
“allocate_explanation” : “cannot allocate because a previous copy of the primary shard existed but can no longer be found on the nodes in the cluster”,
[/cc]4. 一个简单粗暴的移除 red state 的方法是把 red state 的 index 删除掉,这样 Elasticsearch 可以继续接受到日志,不至于影响新进来的日志。
[cc lang=”text”]
$ curl -XDELETE ‘localhost:9200/index_name/’
[/cc]据了解,更靠谱的方法应该是,relocate 这个 shard, 这样不至于丢失整个 index 的数据。然而我没有尝试。
-
rpm -V 没有检测到某些 missing 文件
通常,我们会用 rpm -V
来检查某个 rpm 包的完整性。例如:
[cc lang=”text”]
# mv /usr/share/zoneinfo/zone1970.tab /tmp/
# rpm -V tzdata-2019c-1.el8.noarch
missing /usr/share/zoneinfo/zone1970.tab
[/cc]不过,我遇到的情况是,ca-certificates 这个 rpm 包对应的 /etc/pki/ca-trust/extracted/openssl/ca-bundle.trust.crt 文件被意外移除后,用 rpm -V ca-certificates 这个命令没有检测到它 missing.
[cc lang=”text”]
# rpm -ql ca-certificates | grep ca-bundle.trust.crt
/etc/pki/ca-trust/extracted/openssl/ca-bundle.trust.crt
/etc/pki/tls/certs/ca-bundle.trust.crt
# mv /etc/pki/ca-trust/extracted/openssl/ca-bundle.trust.crt /tmp/
# rpm -V ca-certificates | wc -l
0
[/cc]查看 rpm 包的 ca-certificates.spec 可以看到,extracted 目录下的文件是后期生成了,在 %files 下,会用 %ghost 来标记 extracted 目录下的文件。于是 rpm -ql 能看到这些文件属于这个 rpm 包,但是 rpm -V 的时候不会校验这些文件。
[cc lang=”text”]
# files extracted files
%ghost %{catrustdir}/extracted/pem/tls-ca-bundle.pem
%ghost %{catrustdir}/extracted/pem/email-ca-bundle.pem
%ghost %{catrustdir}/extracted/pem/objsign-ca-bundle.pem
[/cc]参考:
http://ftp.rpm.org/max-rpm/s1-rpm-inside-files-list-directives.html -
安装并使用 xrdp 连接 ubuntu 桌面
公司的电脑是 Windows 10, 不给管理员权限,什么都干不了。 在不买新电脑的前提下,只好通过远程连接到 AWS 的 Ubuntu 桌面上工作。 记录一下安装方法。环境
– AWS
– Ubuntu 18.04
(更多…) -
Namespace 在 Kernel 里是怎么实现的?以 mount namespace 为例
有很多文章都介绍了在应用层面怎么调用 CLONE 的参数来进行 namespace 隔离,于是好奇 namespace 在 kernel 层面是怎么实现的,比如 kernel 需要做哪些改动来提供 namespace 的功能。
应用层面进行namespace隔离的方法
对于应用程序,例如 docker, 可以通过调用 clone(), unshare(), setns() 来对 namespace 进行操作。Coolshell 有几篇通俗易懂的文章可供详细了解[1].
(更多…) -
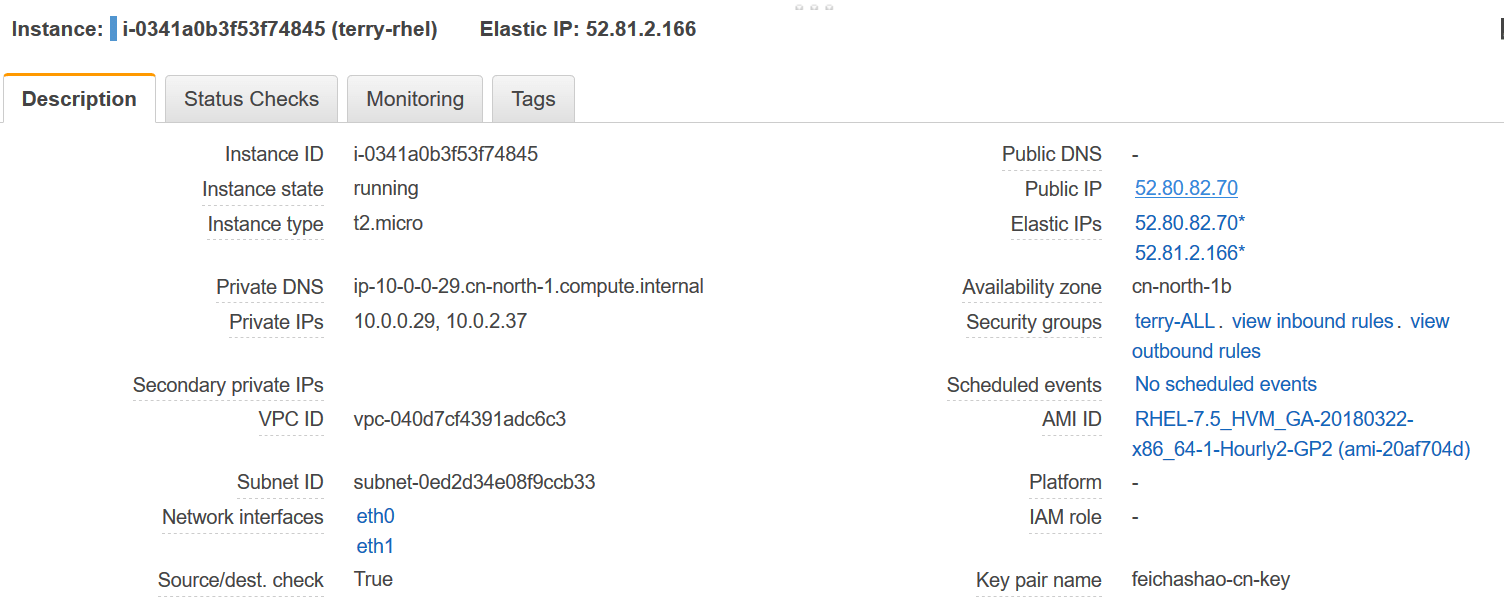
EC2两张网卡连接两个子网,分别关联EIP,其中一个EIP ping不通,怎么办?
问题

– 一个有两张网卡的 EC2 instance (RHEL7.5),每个网卡分别对应一个public subnet, 每个网卡也关联一个 Public IP.
– 从其他网络 ping 这两个 IP 地址,发现其中一个IP能ping通,另一个IP不能ping通。
[cc lang=”text”]
[ec2-user@ip-172-31-30-14 ~]$ ping 52.80.82.70 -c2
PING 52.80.82.70 (52.80.82.70) 56(84) bytes of data.
64 bytes from 52.80.82.70: icmp_seq=1 ttl=63 time=1.71 ms
64 bytes from 52.80.82.70: icmp_seq=2 ttl=63 time=1.80 ms[ec2-user@ip-172-31-30-14 ~]$ ping 52.81.2.166 -c2
PING 52.81.2.166 (52.81.2.166) 56(84) bytes of data.— 52.81.2.166 ping statistics —
2 packets transmitted, 0 received, 100% packet loss, time 1004ms
[/cc] -
How to build a cman + rgmanager cluster environment in KVM
Below are the steps to build a simple cman + rgmanager based cluster environment in KVM. I write down the steps for future reference. Check https://feichashao.com/pacemaker/ for building pacemaker environment (Chinese edition).
(更多…) -
agetty 是做什么的?
有时候在 “ps aux” 命令的输出中,可以看到以下进程:
[cc lang=”text”]
/sbin/agetty –noclear tty1 linux
[/cc]
这个进程是怎么来的?
(更多…) -
rt_sigtimedwait() 使用示例
问题
用户反映某备份软件要花费4-7分钟才能连接上,然后从 strace 中看到 rt_sigtimedwait 这个系统调用耗用了将近3分钟。
[cc lang=”text”]
777 09:28:20.256729 rt_sigtimedwait([INT QUIT TERM XCPU XFSZ PWR], NULL, NULL, 8
777 09:30:55.672016 <... rt_sigtimedwait resumed> ) = 2 <155.415104>
[/cc]
为什么 rt_sigtimedwait 会消耗大量时间呢?
(更多…) -
在RHEL6搭建 LVS Load Balancer
环境

简单的LVS架构 来源: redhat.com feichashao_RHEL610_real-server-0 192.168.122.152
feichashao_RHEL610_real-server-1 192.168.122.9
feichashao_RHEL610_lvs_router 192.168.122.146VIP: 192.168.122.108
在这个环境中,有一个 LVS router 和两个 Real Server. LVS Router 负责把流量转发到 Real Server 中, Real Server 是真正处理请求的。
(更多…)