目标
第三个作业,是实现在模拟器上的“自动驾驶”。这个作业要训练出一个模型,模拟器给出汽车前置摄像头的图像作为输入,模型要输出一个方向(往左或往右多少)。
因为会用到 Keras 框架,所以本文会先简单介绍 Keras. 由于课程还提到了 Transfer Learning, 所以也整理上笔记。
Keras
Keras 是一个high-level的神经网络框架,它是建立在Tensorflow(或CNTK/Theano)之上的框架。它封装好了常用的 layer,可以减轻建立测试模型的工作量。
比如,可以这样创建一个网络:
[cc lang=”python”]
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Flatten
#Create the Sequential model
model = Sequential()
#1st Layer – Add a flatten layer
model.add(Flatten(input_shape=(32, 32, 3)))
#2nd Layer – Add a fully connected layer
model.add(Dense(100))
#3rd Layer – Add a ReLU activation layer
model.add(Activation(‘relu’))
#4th Layer – Add a fully connected layer
model.add(Dense(60))
#5th Layer – Add a ReLU activation layer
model.add(Activation(‘relu’))
[/cc]
只需要指定输入的大小 32x32x3,以及每一层的输出大小,Keras会帮忙打点好其他事情。
训练一个模型也很简单:
[cc lang=”python”]
model.compile(‘adam’, ‘categorical_crossentropy’, [‘accuracy’])
history = model.fit(X_normalized, y_one_hot, nb_epoch=10, validation_split=0.2)
[/cc]
使用训练好的模型进行预测:
[cc lang=”python”]
metrics = model.evaluate(X_normalized_test, y_one_hot_test)
[/cc]
Transfer Learning
要训练一个CNN,需要有大量的数据吗?不一定。我们可以借用已经训练好的模型,用自己的数据加以调整,即可用不多的数据,训练出想要的模型。
比如说,我们已经有一个模型可以判断“犬类动物”和“猫科动物”,而我们想进一步判断“狼狗”还是“二哈”,那么我们可以在已经训练好的模型的基础上,用自己的数据进一步训练。
![]()
![]()
如果自己的数据不多,可以考虑至训练最后一层。如果数据比较多,可以多训练几层。
课程模拟器
课程用的模拟器可以从以下地址下载:
https://github.com/udacity/self-driving-car-sim
按照上面链接的文档安装好模拟器。
在训练模式下,键盘按上箭头,可以使小车加速,按下箭头使小车减速。按住鼠标左键,左移/右移鼠标控制方向。按下R可开启记录模式,在记录模式下,模拟器会记录小车摄像头看到的图像,以及当前(鼠标给出的)方向大小。
退出训练模式后,它会将刚刚记录的数据,输出到 IMG 目录和 driving_log.csv 文件中。前者是小车左中右三个摄像头记录的图像,后者记录图像对应的控制量。


自动模式下,模拟器会通过网络接口与 drive.py 连接。drive.py 可从以下链接获取:
https://github.com/udacity/CarND-Behavioral-Cloning-P3
在运行时,模拟器会给 drive.py 传输小车前置摄像头的图像,然后 drive.py 需要返回一个方向控制量,模拟器根据方向控制量调整方向。
采集训练数据
在训练之前,首先要有训练数据。
采集正常行驶的数据:
– 以匀速前行,尽可能地靠近中线行驶,尽可能驾驶平稳(不要抖)。
– 正常行驶的数据应该多采集,因为小车在多数情况下是正常行驶的。

采集非中线行驶的数据:
– 如果在自动驾驶时,小车拐到了车到边缘,或者卡在拐弯位的某处,我们需要教会它自己走出来。
– 暂停记录模式,缓缓把车开到车道边缘,开启记录模式,使劲拐弯使小车走回中线。
– 暂停记录模式,缓缓把车开到拐弯处,模拟拐不出来的情况,开启记录模式,使劲拐弯使之回到正常路上。

数据预处理
在将数据喂给模型之前,要先预处理数据。
– 首先,可以复制出左右对称的数据。例如,将图形左右翻转,对应的方向控制量也左右翻转(从左变成右)。这样,训练数据量就加倍了,而且使得左右控制量的分布是一样的。


– 然后是 Normalize (归一化)。将图像的像素值从 0-255 映射到 -0.5 ~ 0.5,使之中心为0.
– 图像裁剪。图像的上方大多是天空,不涉及道路,可以裁剪掉,减少数据大小。
– 把左右摄像头得到的图像转变成“中间摄像头”的图像。记录模式会记录左中右三个前置摄像头的图像。在实际应用中,只会使用中间的摄像头作为输入。左右两边的摄像头看到的图像,相当于中间摄像头在道路偏左和道路偏右的情况下看到的图像,所以我们可以把左右摄像头的图像,用作输入,然后把方向控制量人为地添加偏移即可。例如,左边摄像头的图像,将方向控制量向右偏移0.2,可以看作是中间摄像头在道路偏左的时候对应的控制量。
最终处理完的数据集分布如图。横轴是控制量(负是左,正是右),纵轴是对应图片的数量。
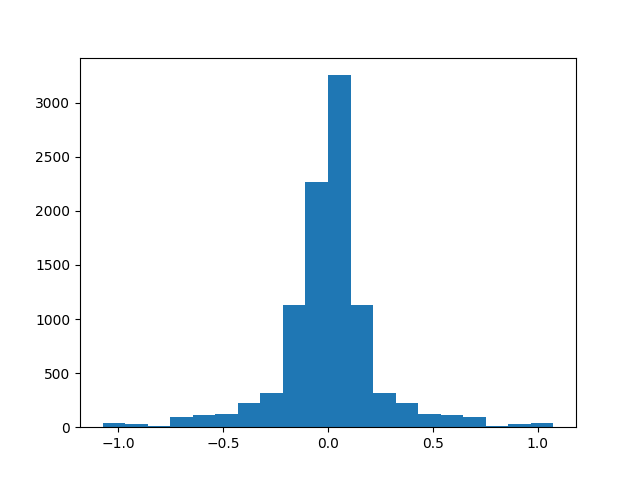
图片预处理的代码实现如下。最终得到 X_train 和 y_train 作为训练数据。X_train 是图像,y_train 是对应的方向控制量。
[cc lang=”python”]
### Read Training data
import csv
import cv2
import numpy as np
lines = []
with open(‘train/driving_log.csv’) as csvfile:
reader = csv.reader(csvfile)
for line in reader:
lines.append(line)
# ignore the csv header
lines.pop(0)
# Put the filename and measurement into seperated array.
images = []
measurements = []
for line in lines:
source_path = line[0]
tokens = source_path.split(‘/’)
filename = tokens[-1]
local_path = ‘./train/IMG/’ + filename
image = cv2.imread(local_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
images.append(image)
measurement = float(line[3]) * 1.5 # Amplify the measurement.
measurements.append(measurement)
print(“images: ” + str(len(images)))
print(“measurements: ” + str(len(measurements)))
## Flip the images
augmented_images = []
augmented_measurements = []
for image, measurement in zip(images, measurements):
augmented_images.append(image)
augmented_measurements.append(measurement)
flipped_image = cv2.flip(image, 1)
flipped_measurement = measurement * -1.0
augmented_images.append(flipped_image)
augmented_measurements.append(flipped_measurement)
print(“augmented_images: ” + str(len(augmented_images)))
print(“augmented_measurements: ” + str(len(augmented_measurements)))
X_train = np.array(augmented_images)
y_train = np.array(augmented_measurements)
[/cc]
网络模型
神经网络的模型基于 Nvidia End-to-End pipeline. 前面是几层 Convolution,后面接着基层 Fully Connected.

[cc lang=”text”]
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
===============================================
lambda_1 (Lambda) (None, 160, 320, 3) 0 lambda_input_1[0][0]
____________________________________________________________________________________________________
cropping2d_1 (Cropping2D) (None, 65, 320, 3) 0 lambda_1[0][0]
____________________________________________________________________________________________________
convolution2d_1 (Convolution2D) (None, 31, 158, 24) 1824 cropping2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_2 (Convolution2D) (None, 14, 77, 36) 21636 convolution2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_3 (Convolution2D) (None, 5, 37, 48) 43248 convolution2d_2[0][0]
____________________________________________________________________________________________________
convolution2d_4 (Convolution2D) (None, 3, 35, 64) 27712 convolution2d_3[0][0]
____________________________________________________________________________________________________
convolution2d_5 (Convolution2D) (None, 1, 33, 64) 36928 convolution2d_4[0][0]
____________________________________________________________________________________________________
flatten_1 (Flatten) (None, 2112) 0 convolution2d_5[0][0]
____________________________________________________________________________________________________
dense_1 (Dense) (None, 100) 211300 flatten_1[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 50) 5050 dense_1[0][0]
____________________________________________________________________________________________________
dense_3 (Dense) (None, 10) 510 dense_2[0][0]
____________________________________________________________________________________________________
dense_4 (Dense) (None, 1) 11 dense_3[0][0]
===============================================
Total params: 348,219
Trainable params: 348,219
Non-trainable params: 0
____________________________________________________________________________________________________
[/cc]
用 Keras 实现如下。训练好的模型用 model.save() 存放成文件,供后续 drive.py 自动驾驶使用。
[cc lang=”python”]
### Define model and train.
import keras
from keras.models import Sequential
from keras.layers import Flatten, Dense, Lambda
from keras.layers.convolutional import Convolution2D, Cropping2D
from keras.layers.pooling import MaxPooling2D
model = Sequential()
model.add(Lambda(lambda x: x / 255.0 – 0.5, input_shape=(160, 320, 3))) ## Normalize input.
model.add(Cropping2D(cropping=((70,25),(0,0))))
# Nvidia end to end pipeline
model.add(Convolution2D(24,5,5,subsample=(2,2),activation=’relu’))
model.add(Convolution2D(36,5,5,subsample=(2,2),activation=’relu’))
model.add(Convolution2D(48,5,5,subsample=(2,2),activation=’relu’))
model.add(Convolution2D(64,3,3,activation=’relu’))
model.add(Convolution2D(64,3,3,activation=’relu’))
model.add(Flatten())
model.add(Dense(100))
model.add(Dense(50))
model.add(Dense(10))
model.add(Dense(1))
model.compile(optimizer=’adam’, loss=’mse’)
model.fit(X_train, y_train, validation_split=0.2, shuffle=True, nb_epoch=3)
model.save(‘model-nv-0330-8.h5’)
[/cc]
训练时使用’adam’作为 optimizer,省去了调整 learning rate 的烦恼。
训练模型
训练上述模型(模型1),用20%的数据作为 Validation,得到的 Loss 如下图。Training error 一直在下降,而 Validation error 却不断提高。这是 overfitting 的表现。

为了减少 overfitting, 尝试加入 dropout layer,模型如下:
[cc lang=”text”]
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
=====================================================
lambda_1 (Lambda) (None, 160, 320, 3) 0 lambda_input_1[0][0]
____________________________________________________________________________________________________
cropping2d_1 (Cropping2D) (None, 65, 320, 3) 0 lambda_1[0][0]
____________________________________________________________________________________________________
convolution2d_1 (Convolution2D) (None, 31, 158, 24) 1824 cropping2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_2 (Convolution2D) (None, 14, 77, 36) 21636 convolution2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_3 (Convolution2D) (None, 5, 37, 48) 43248 convolution2d_2[0][0]
____________________________________________________________________________________________________
convolution2d_4 (Convolution2D) (None, 3, 35, 64) 27712 convolution2d_3[0][0]
____________________________________________________________________________________________________
convolution2d_5 (Convolution2D) (None, 1, 33, 64) 36928 convolution2d_4[0][0]
____________________________________________________________________________________________________
flatten_1 (Flatten) (None, 2112) 0 convolution2d_5[0][0]
____________________________________________________________________________________________________
dense_1 (Dense) (None, 100) 211300 flatten_1[0][0]
____________________________________________________________________________________________________
dropout_1 (Dropout) (None, 100) 0 dense_1[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 50) 5050 dropout_1[0][0]
____________________________________________________________________________________________________
dense_3 (Dense) (None, 10) 510 dense_2[0][0]
____________________________________________________________________________________________________
dense_4 (Dense) (None, 1) 11 dense_3[0][0]
======================================================
Total params: 348,219
Trainable params: 348,219
Non-trainable params: 0
[/cc]
分别尝试 dropout=0.2 (每次随机关闭该层20%的连接)(模型2) 和 dropout=0.5 (模型3),训练结果如图。


overfitting 减缓了,但是错误率一直不下降。
上路测试
指定训练好的模型 model.h5, 运行 drive.py.
[cc lang=”bash”]
python drive.py model.h5
[/cc]
等 drive.py 成功监听http端口后,启动模拟器的 Autonomous Mode, 即可在模拟器中测试模型。
在模拟器中,使用模型1,epcho=3,小车可以跑下来一圈,尽管中间有些偏离中线。使用模型2和模型3,虽然看上去没有overfitting,但是在路上跑的时候突然就跑飞了。
调整优化
在得出上面那个可以勉强跑下来的模型之前,尝试了大概20次不同数据不同模型的训练。优化调整主要有模型和数据两部分。
模型:
最开始使用了LeNet,training loss 不高,但是在模拟器中跑起来,效果很差。(一直走直线,直到掉水里)
论坛上的同学们推荐使用 Nvidia 的模型,效果好多了。(用了跟LeNet一样的训练数据,虽然还是掉水里,但能稍微拐弯了)
训练数据:
在这个作业中,模型基本是 Nvidia 的,没有什么改动。训练数据的质量显得更重要。
分多次采集了数据,每组数据对应不同的情况。有几组正常行驶的数据,有几组专门记录拐弯位的数据,有几组偏离中线的数据。几个之间组合一下,作为一个整体的数据进行训练。
最后找到一组能完成一圈的训练数据,但是发现拐弯没劲,于是在处理数据的时候,手动对所有方向控制量都乘以1.5,放大拐弯幅度。
经验总结
– 珍爱生命,使用GPU. 我没有GPU,当时也没有信用卡用不到AWS,只好用笔记本的CPU硬跑。基本上几千张图片的训练量,大概耗时2小时。每次调整重试都是煎熬。
– 在这个作业中,数据比模型重要。Behavior cloning, 要让模型“见过大风大浪”,它才能跑得更好。
参考资料
[1] Python generator 的介绍。数据量大的时候可以用来节省内存占用。
https://stackoverflow.com/questions/231767/what-does-the-yield-keyword-do
[2] End to End Learning for Self-Driving Cars 作业用到的模型
https://images.nvidia.com/content/tegra/automotive/images/2016/solutions/pdf/end-to-end-dl-using-px.pdf
[3] Simulator 作业用到的模拟器
https://github.com/udacity/self-driving-car-sim
[4] CarND Behavioral Cloning repo
https://github.com/udacity/CarND-Behavioral-Cloning-P3